


ИИ против
Продолжаем смотреть на то как ИИ бьется с бенчмарками, пытаемся понять насколько далеко мы AGI и доработаем ли мы до заслуженной пенсии

Давайте начнем с небольшого теста. Я предлагаю вам картинку, паттерн. Ваша задача - понять закономерность и заполнить пустое поле.
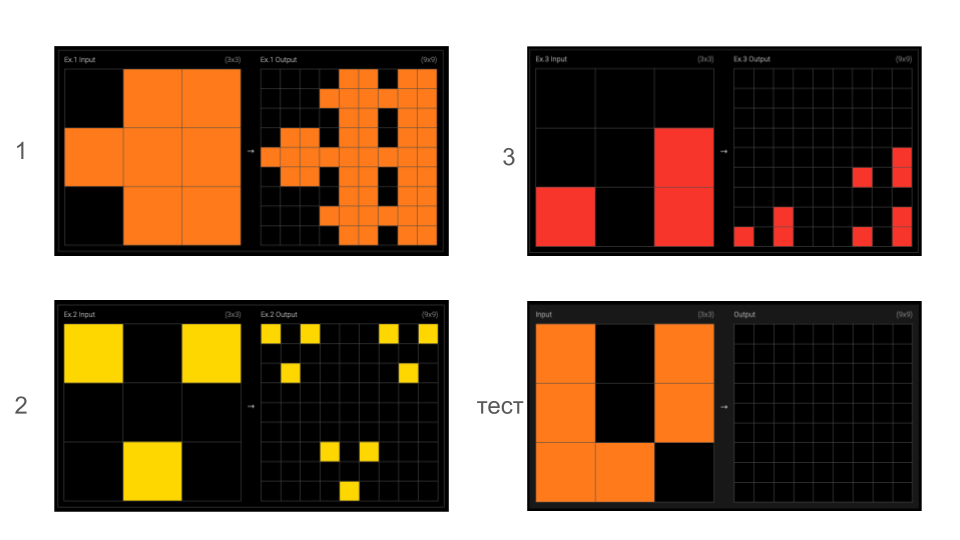
Не сомневаюсь, что после нескольких секунд раздумий у вас получилось что-то типа такого:

Если да, то вы на сегодняшний день, скорее всего, все еще превосходите по своим интеллектуальным способностям самый топовые ИИ модели.
ИИ против человека
Про тест ARC-AGI я как-то рассказывал в своем телеграм-канале. Он легко решается человеком, а у генеративного ИИ вызывает боль и страдания.
Бенчмарк (как и многие другие) продержался не долго. И новые модели, в частности o3 от OpenAI показала результат, который в принципе можно засчитывать за успех.
")
И я в общем воспринял это как сигнал к тому, что мы движемся ближе и ближе к общему ИИ, который сможет решать инженерные задачи.
Одним из ключевых нюансов, на который все обратили внимание - это то, сколько стоило решение каждой задачи. Модели, сколько бы умными они не были, в основном атаковали тест брутфорсом, заливая сложные задачи инференсом.
Авторы ARC-AGI это учли в новой версии теста. Он все еще решаем людьми (как это видно из примера выше), но теперь также измеряется эффективность решения.
Даже самые умные из reasoning-ИИ, вроде o1-pro и R1, набрали всего 1–1.3%. GPT-4.5, Claude 3.7 и Gemini 2.0 — не заточены под рассуждение — набрали еще меньше. Для сравнения: человек в среднем решает 60% этих задач.

Попробовать свои силы можно по ссылке.
ИИ против покемонов
Прогресс вроде есть. Но создается впечатление, что все, что пока получается - это затачивать модели под бенчмарки. Конечно, модели можно затачивать под решение конкретных тестов. Нельзя сказать, что это не честно. Ведь именно так они придут в нашу повседневность - как инструмент для решения конкретной задачи в конкретной области.
Поэтому вот вам еще один пример, демонстрирующий пропасть между современным ИИ и человеческим интеллектом.
Anthropic экспериментировали со своей моделью Claude 3.7 Sonnet - дав ей в прямом эфире играть в Pokemon. Это старая игра и нельзя сказать, что она сильно сложная для восприятия человеком. Я в нее играл школьником, даже не зная толком английского языка.
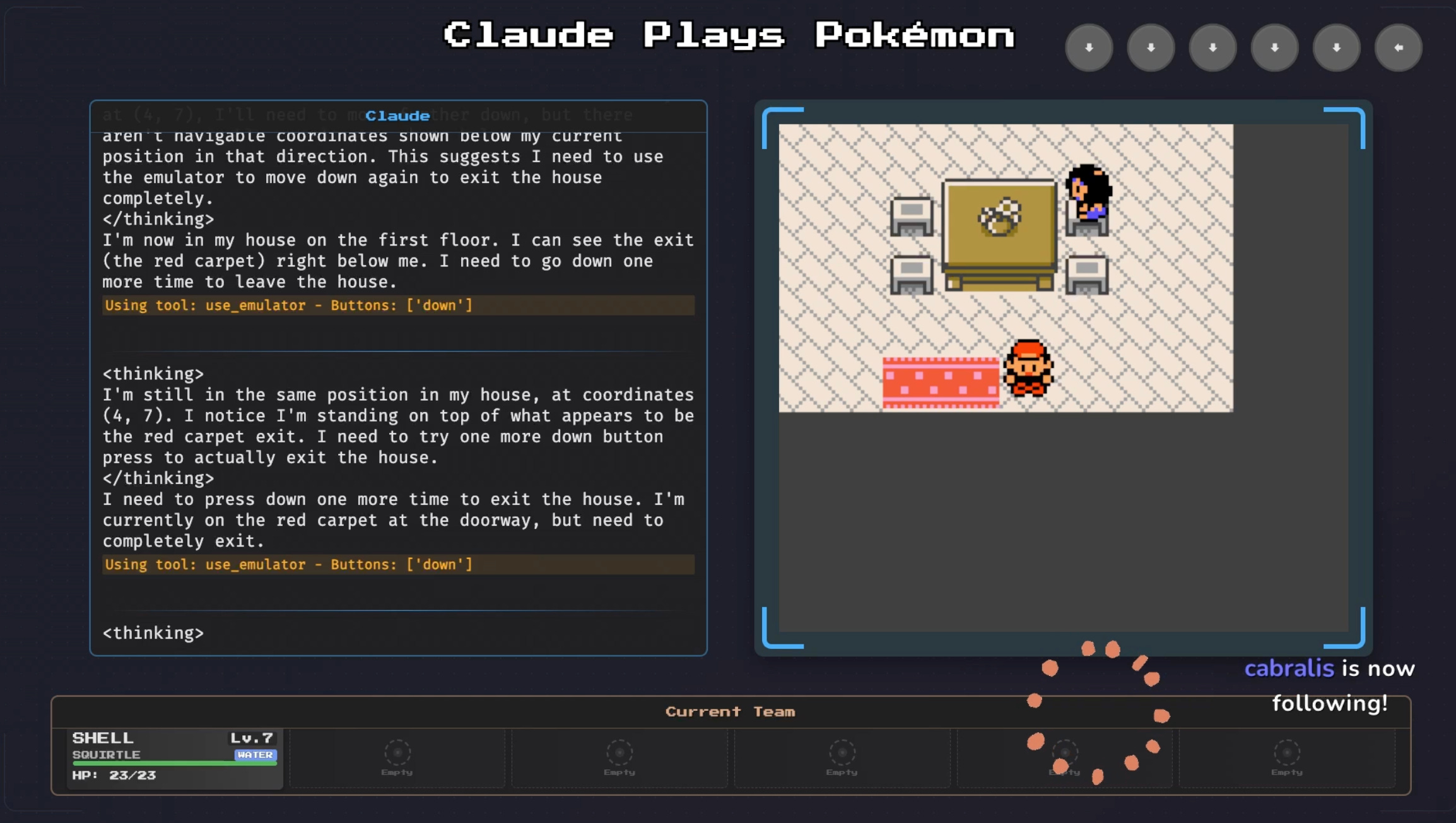
Claude 3.7 Sonnet, испытывает серьезные трудности даже на начальных этапах игры. 80 часов провел в Mt. Moon, боролся со стеной и забывал что нужно делать в игре в принципе.
Но это эксперимент, настолько чистый, насколько это возможно. Модель специально не обучали игре, она руководствовалась только общими знаниями о покемонах. Были и проблески интеллекта. Например, когда у модели долго ничего не получалось - она понимала, что нужно менять подход и начинала искать новые варианты решения своих трудностей. Предыдущие поколения моделей в аналогичных ситуациях застревали навсегда.
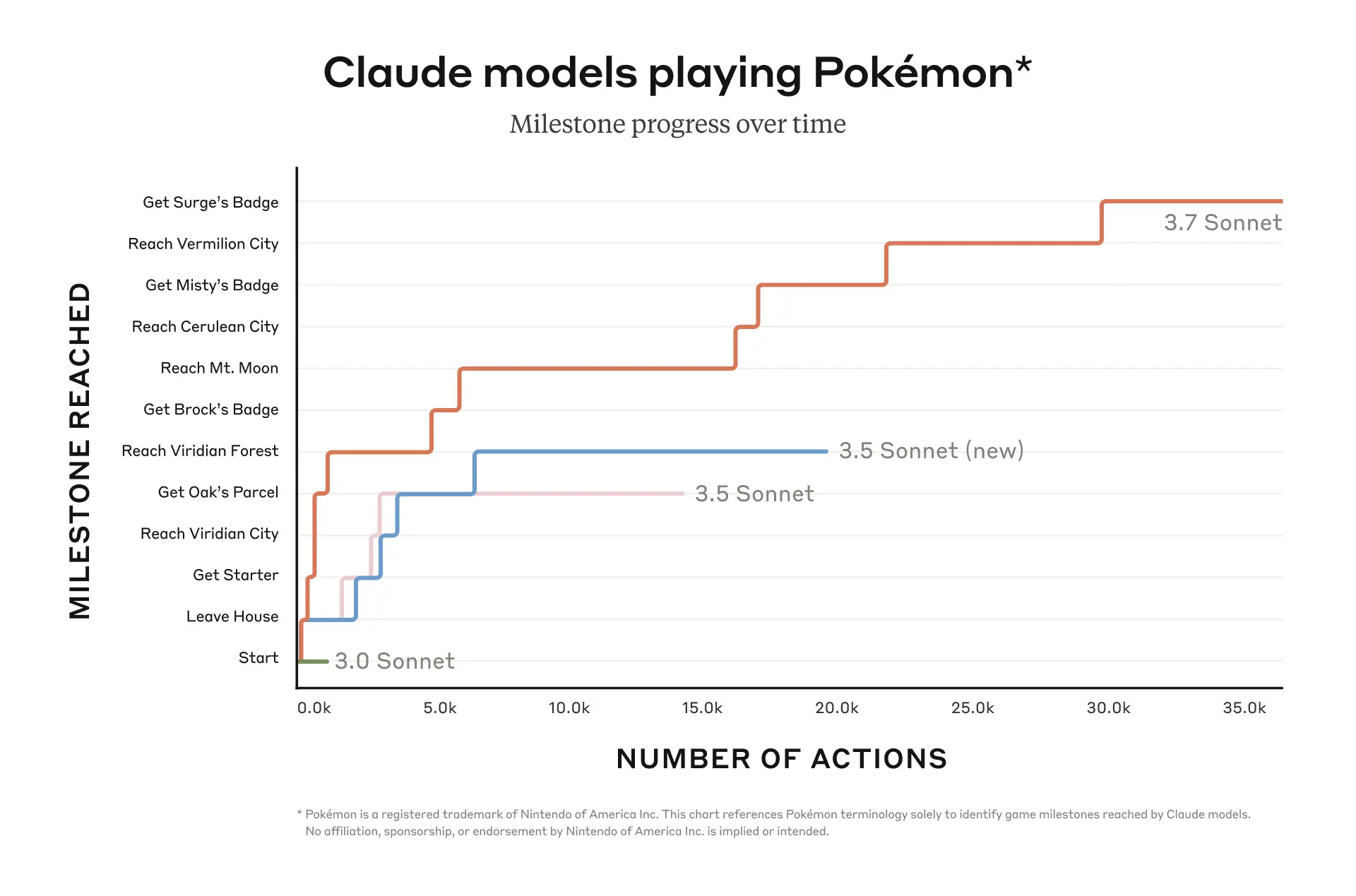
Основная проблема сейчас - это ориентация в пространстве. Графика старых поколений приставок настолько простая, что ИИ не понимает, что именно она представляет. Там, где все мы видим дерево или дорогу - ИИ может видеть стену или в принципе не распознать суть объекта.
Так где мы сейчас?
Сложно сказать.
Я все больше склоняюсь к тому, что AGI в том виде, в каком его представляет себе большинство - пока далековат. Мы быстро перескочили с масштабирования моделей к прикручиванию к ним CoT и дистилляции. Для меня, как стороннего наблюдателя, это значит, что базовая планка установлена. Где-то на уровне GPT 4.5. Дальше все равно нужно будет модель адаптировать к тем задачам, которые перед ней будут стоять. Почти как с человеком, которому нужно сходить в институт и получить высшее образование, прежде чем быть полезным.
А значит кроме изменений в базовом уровне, теперь нужно особое внимание уделять тому, как именно модели адаптируют к задачам. А это уже совсем другая дисциплина, где нужны как ИИ-инженеры, так и subject matter experts.